
Science:利用Meta AI开发的ESMFold语言模型快速进行蛋白结构预测
来源:生物谷原创 2023-03-30 09:27
Meta AI的Facebook AI研究院(FAIR)的研究人员在Science期刊上详细介绍了一个利用机器学习构建的6.17亿个预测蛋白结构的数据库。
Meta AI的Facebook AI研究院(FAIR)的研究人员在2023年3月17日的Science期刊上发表了一篇标题为“Evolutionary-scale prediction of atomic-level protein structure with a language model”的论文,详细介绍了一个利用机器学习构建的6.17亿个预测蛋白结构的数据库。ESMFold语言模型对这些结构的描述比DeepMinds AlphaFold2快60倍,尽管报告的准确率较低。
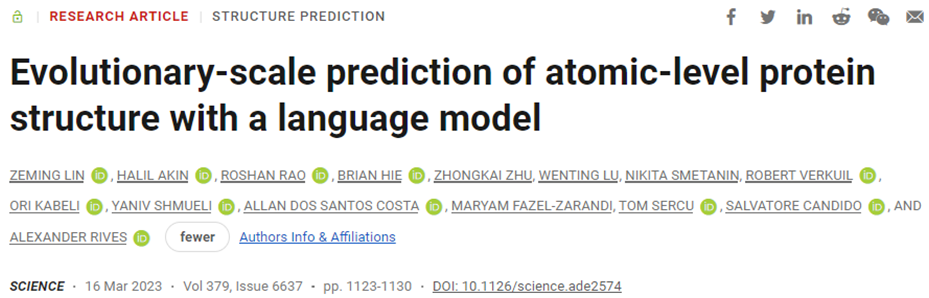
这些蛋白折叠预测在大约2000个GPU的集群上仅用两周时间就完成了。最初的序列长度从20到1024个核苷酸不等。3.65亿次的预测具有良好的可信度,大约2.25亿次的预测具有高度可信的准确性。
根据这篇论文,对100万个高置信度结果的随机抽样显示,767580种蛋白与UniRef90(一个已知蛋白序列的数据库)中的任何序列的序列一致性低于90%。这些作者认为,这表明这些蛋白与现有的UniRef90序列不同。
随后,这些作者将预测结构样本与三维蛋白结构数据库Protein Data Bank(简称PDB)中的已知结构进行比较。在阈值为0.5TM-score时,12.6%(125765种蛋白)没有结构成分匹配。基于此,他们估计,大约2800万种具有高置信度预测的蛋白(2.25亿中的12.6%)可能存在与现有知识有无法描述的蛋白结构区域。
基于序列的预测
蛋白开始于DNA经转录后产生的信使RNA(mRNA)。接着,所产生的的mRNA被翻译成一条氨基酸链。然后,这条氨基酸链经历了不可思议的转变,变成复杂的三维折叠形状,根据其折叠结构,执行特定的复杂的细胞功能。
蛋白或酶如何折叠在一定程度上决定了它的功能,因为它限制和优化了它能与什么相互作用。这种结构形成了一个开口或一把“锁”,只有与正确的分子“钥匙”配合时才能运作。从食品工业和啤酒酿造到纺织品和生物燃料,人们一直在使用这样的酶,但是没有详细了解蛋白究竟是如何折叠的。
图片来自Science, 2023, doi:10.1126/science.ade2574。
衣用洗涤剂通常包含几种类型的酶,其中的一些是分解植物材料的纤维素酶。当纤维素酶遇到来自草渍的纤维素时,纤维素就变成了开启这把锁的钥匙。该酶引发了化学反应,分解了草渍中的纤维素。同样的酶在遇到口红或油脂污渍时不会做什么,这可能是另一种酶的工作。
一种蛋白酶可能每秒执行数千甚至数百万次的任务而不中断,为工业界提供了一个低能量的催化剂,使酶成为一种工具性技术。
我们身体的每种系统也依靠蛋白来执行生物功能。由于蛋白的折叠结构对其能够从事的活动至关重要,在探究疾病原因时,了解这种结构对了解它们如何工作至关重要。
根据氨基酸的一级序列预测蛋白将如何折叠的能力将使医学研究人员更好地了解蛋白-代谢物相互作用和整个身体的生物功能。这种更高分辨率的理解可能识别隐藏的疾病特征,加快研究新的或更好的治疗方法,并在某种程度上彻底改变现代医学。准确了解结构如何跟随氨基酸的一级序列的形式,也将使科学家们能够构建定制的蛋白,以执行医疗保健和工业领域的特定任务。
在人工智能预测模型之前的几十年里,科学家们对大约19万种感兴趣的蛋白的结构进行了建模。机器学习如今已产生了数以亿计的预测,这些预测仍然需要确认和研究才能发挥作用。虽然仍然不够可靠,无法取代速度较慢的X射线晶体学的蛋白结构确定或受控测定实验的功能,但人工智能才刚刚开始。在未来的几十年里获得的知识可能会使之前的一切黯然失色。(生物谷 Bioon.com)
参考资料:
Zeming Lin et al. Evolutionary-scale prediction of atomic-level protein structure with a language model. Science, 2023, doi:10.1126/science.ade2574.
版权声明 本网站所有注明“来源:生物谷”或“来源:bioon”的文字、图片和音视频资料,版权均属于生物谷网站所有。非经授权,任何媒体、网站或个人不得转载,否则将追究法律责任。取得书面授权转载时,须注明“来源:生物谷”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
