
Nat Biotechnol:提供对翻译开放阅读框的标准化注释
来源:生物谷原创 2022-08-02 15:06
当参与人类基因组计划(Human Genome Project)的科学家们在2001年完全绘制出人类的遗传蓝图时,他们惊讶地发现只有大约2万个表达蛋白的基因。难道说人类的基因数量只有普通苍蝇的两倍?
当参与人类基因组计划(Human Genome Project)的科学家们在2001年完全绘制出人类的遗传蓝图时,他们惊讶地发现只有大约2万个表达蛋白的基因。难道说人类的基因数量只有普通苍蝇的两倍?科学家们曾预期会多得多。
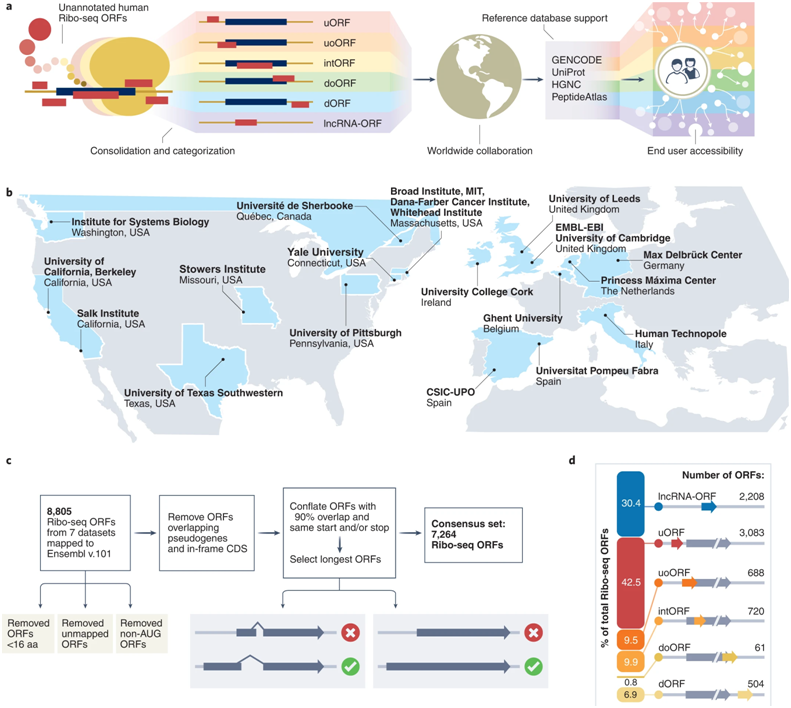
如今,在一项新的研究中,来自全世界20个研究机构的研究人员将7200多个未被识别的潜在地编码新蛋白的基因片段汇集在一起。该研究首次利用一种新技术来寻找人类中的潜在蛋白---详细观察细胞中的蛋白产生机制。该研究指出人类基因组计划的基因发现工作仅仅是个开始,而且这些作者旨在鼓励科学界将这些数据整合到主要的人类基因组数据库中。

相关研究结果发表在2022年7月的Nature Biotechnology期刊上,论文标题为“Standardized annotation of translated open reading frames”。该研究由德国亥姆霍兹协会马克斯-德尔布吕克分子医学中心(MDC)的Jorge Ruiz- Orera博士、荷兰马西玛公主儿科肿瘤中心的Sebastiaan van Heesch博士、英国欧洲分子生物学实验室-欧洲生物信息学研究所(EMBL-EBI)的Jonathan Mudge博士和美国布罗德研究所的John Prensner博士共同领导。
新的基因序列仍然遥不可及
在过去的几年里,人类基因组中发现了数千个非常小的开放阅读框(open reading frame, ORF)。这些DNA序列可能包含构建蛋白的指令。这项新研究的几位作者之前已经发现了ORF,并在科学杂志上对它们进行了描述:van Heesch与MDC教授Norbert Hübner和Uwe Ohler一起描述了人类心脏中的新的微型蛋白(mini-protein),并在2019年的Cell期刊上进行了报道(Cell, 2019, doi:10.1016/j.cell.2019.05.010);Prensner也在2021年的Nature Biotechnology期刊上发表了关于ORF的文章(Nature Biotechnology, 2021, doi:10.1038/s41587-020-00806-2)。然而,这些以前几乎没有探索过的DNA片段之后都没有被列入参考数据库中。其他ORF序列在Science(Science, 2020, doi:10.1126/science.aay0262)或Nature Chemical Biology(Nature Chemical Biology, 2020, doi:10.1038/s41589-019-0425-0)等期刊上被报道,但对于科学界的大多数成员来说,基本上仍然遥不可及---尽管有证据表明它们产生的RNA分子随后与细胞的蛋白制造工厂--核糖体---结合。
传统上,基因中的蛋白编码区是通过比较多个物种的DNA序列来确定的:在动物进化过程中,最重要的编码区被保留了下来。但是这种方法有一个缺点:相对年轻的编码区,即在灵长类动物的进化过程中产生的编码区会被遗漏,因此在数据库中消失。
因此,现在的任务是将这些基本上被忽视的ORF整合到最大的参考数据库中,因为到目前为止,如果科学家们想要研究它们,就必须在文献中专门搜索它们。
作为第一步,这些作者收集了使用核糖体图谱(ribosome profiling)---一种确定核糖体与信使RNA(mRNA)的哪一部分相互作用的技术---发现的序列信息。然后他们将这些数据汇集成一个标准化的目录。这不是一项小成就,因为从不同实验室以各种方式获得的数据不能简单地合并在一起。
图片来自Nature Biotechnology, 2022, doi:10.1038/s41587-022-01369-0。
一旦完成了这项工作,这些作者就开始研究界定我们人类基因组概念的核心问题:什么是基因?什么是蛋白?我们是否需要灵活的概念来确定核糖体是否总能产生蛋白或者其他细胞输出?
这些作者如今呼吁对全世界科学家使用的人类基因组数据库进行修订。Ensembl-GENCODE正在配置这个ORF目录,作为其参考注释数据库的一个组成部分。这种方法将得到许多其他数据库的支持,如UniProt、HGNC、PeptideAtlas和HUPO。
ORF可能在常见疾病中发挥作用
van Heesch博士说,他们的“研究标志着在了解人类蛋白的基因构成和完整数量方面迈出了一大步。通过我们的新目录使研究界能够进行研究,这是巨大的兴奋。现在说所有未被探索的DNA片段是否真地代表蛋白还为时过早,但我们可以清楚地看到,整个人类基因组中存在着一些未开发的东西,世界应该予以关注”。
Mudge说,“长期以来,科学界对这些ORF大多一无所知。我们非常自豪,我们的研究工作将能够让全世界的科学家们开始研究它们。这是它们进入基因组学和医学科学主流的时刻---我们期望这一努力能产生广泛的连锁反应。”
Ruiz- Orera说,“特别引人注目的是,这7200个ORF中的大多数是灵长类动物所独有的,可能代表了我们物种特有的进化创新。这表明这些DNA元件可以为我们人类的形成提供重要的线索。”
那么,下一步是什么?Prensner说,“这些ORF几乎肯定会成为许多人类性状和疾病(包括罕见的疾病和常见的疾病,比如癌症)的促进因素。现在的挑战是要弄清楚哪些ORF在哪些疾病中有哪些作用。”(生物谷 Bioon.com)
参考资料:
Jonathan M. Mudge et al. Standardized annotation of translated open reading frames. Nature Biotechnology, 2022, doi:10.1038/s41587-022-01369-0.
版权声明 本网站所有注明“来源:生物谷”或“来源:bioon”的文字、图片和音视频资料,版权均属于生物谷网站所有。非经授权,任何媒体、网站或个人不得转载,否则将追究法律责任。取得书面授权转载时,须注明“来源:生物谷”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
