
解码利用AI高效发现靶点的策略,英矽智能发表综述论文
来源:生物世界 2023-08-07 15:56
在广袤的化学空间和海量的“可成药靶点”中,人类已经完成探索的部分少之又少,产学研界迫切需要更高效的靶点识别策略。

文章探讨多种创新靶点发现策略,包括深度学习模型发现靶点、通过实验验证人工智能识别的靶点、以及使用生成式人工智能合成数据辅助靶点发现。除成药性和毒理外,新颖性也是靶点评估的关键因素。靶点的可信度和新颖性之间需要权衡。
英矽智能持续关注前沿AI科技进展,并在其自研Pharma.AI药物发现平台下建设了靶点发现引擎PandaOmics,由超过20种预测模型和生成生物学模型搭建而成,集成千万级组学数据样本、百万级分子信息和数十万级分子相互作用机制等数据。该平台可支持专业的靶点筛选、排序和分析,兼具针对生命科学信息自然语言问答系统和将疾病、基因及药物联系起来的知识图谱功能。
靶点识别概述
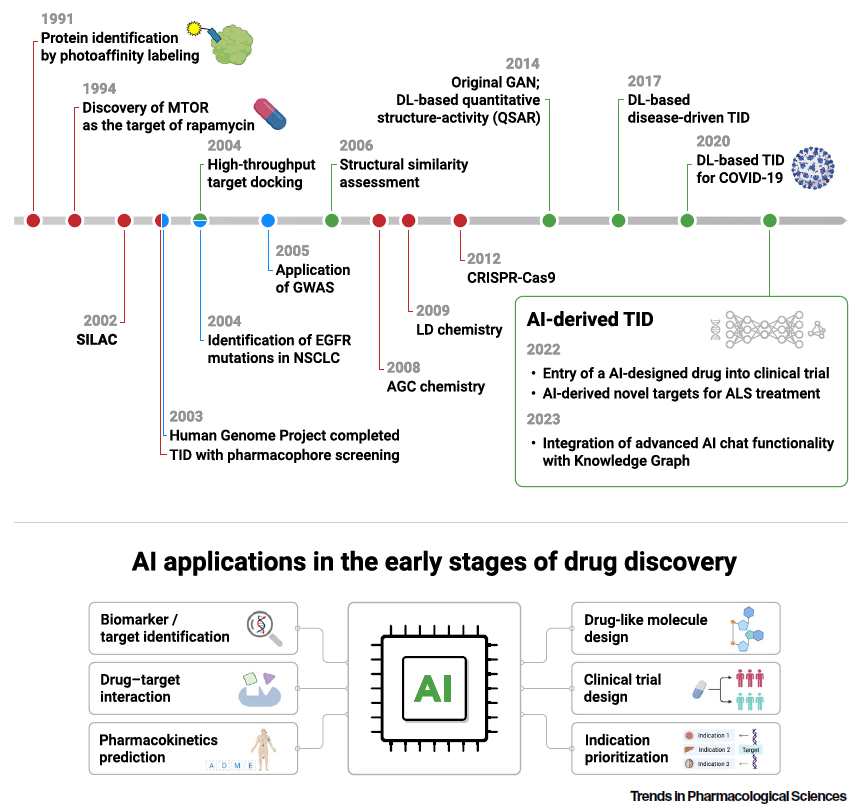
人们普遍认为药物研发过程耗时长、成本高、风险大,将一种新药推向市场通常需要10年左右的时间和20亿美元。到2022年,已经得到验证的成功药物靶点不到500个。相对于人类估计的可成药靶点总数,这只是很小的一个部分。尽管许多候选药物在临床前阶段经过了大量的优化,2009-2018年间临床试验的平均失败率高达84.6%,造成大量的时间和金钱浪费。
候选药物折戟临床试验阶段的主要原因在于未表现出良好临床药效,而适宜的药物靶点是提升成功率的关键因素。
为达到治疗效果,药物分子应当对特定的生物分子或细胞通路进行调节,确认这些“调节目标”的过程就是“靶点识别”,在现代药物发现流程中越发受到重视。尽管过去的几十年见证了实验和组学技术的持续突破创新,但确定可操作的治疗靶点仍然充满挑战。当前,将多组学数据与人工智能算法结合的靶点识别方法正获得关注,被认为具有广阔的应用前景。
1、实验方法
自 20 世纪 60 年代以来,实验方法在靶点识别方面做出了突出贡献,包括基于亲和力的生化方法、比较分析方法和化学遗传筛选方法。其中,采用小分子亲和探针在配体与蛋白质相互作用时对蛋白质进行无痕标记,是最为直接的一种方法。探针的选择在很大程度上取决于起始分子的特性。
细胞培养条件下稳定同位素标记技术(Stable isotope labeling by amino acids in cell culture,SILAC)则是比较分析的一个例子。这是一种较为常用的定量蛋白质组学工具,利用稳定同位素标记的氨基酸来准确区分细胞蛋白质组。在肝细胞癌(HCC)、多发性骨髓瘤、子宫内膜癌和结肠直肠癌等多种癌症类型中进行的研究清楚地证明了SILAC确定疾病发病关键机制的作用。
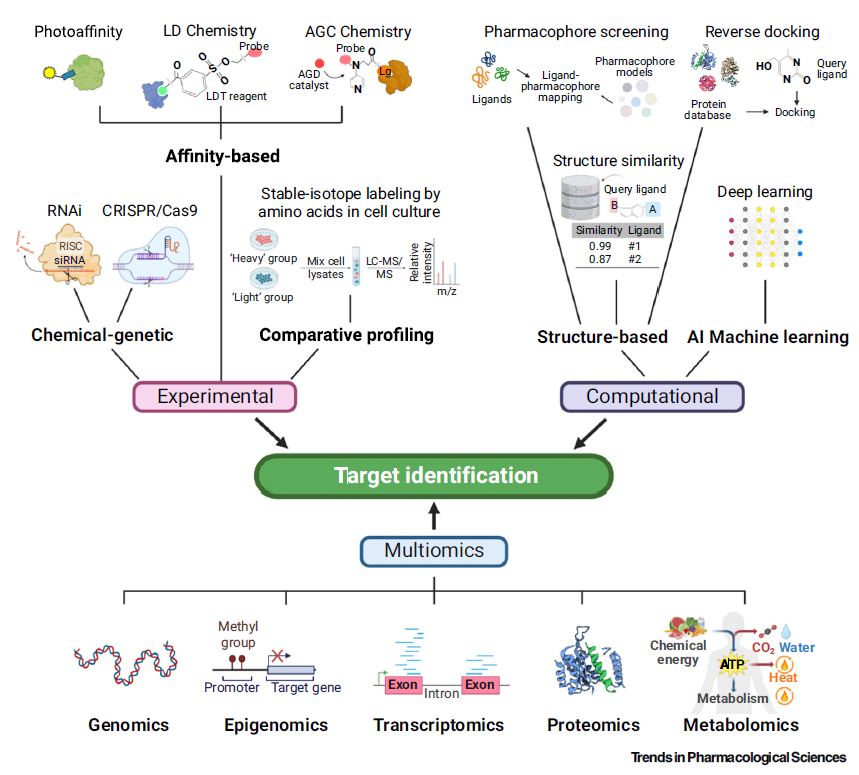
2、多组学方法
多组学数据为研究人员提供了来自不同方面的相互关联的分子信息,包括静态基因组数据、时空动态表达水平、代谢数据。
作为建立最早、发展最成熟的组学学科,基因组学主要研究 DNA 序列中的遗传变异,是靶点识别中不可缺少的因素,但针对导致特定疾病的致病基因变异的区分仍有困难,有望从多种组学数据的整合中获益。
除基因组学外,转录组学和蛋白质组学数据可用于确定调控基因和蛋白质水平的致病基因位点,并有助于发现疾病致病基因和途径;表观基因组学和代谢组学数据也可作为GWAS确定变异的功能证据,支持其与疾病的关联和临床应用。
3、计算辅助方法
由于典型的基于实验的靶点识别既费力又耗费资源,计算方法已成为实现高效筛选的替代方法,具有广阔的应用前景。根据蛋白质结构和相关化合物化学结构的可用性,药效筛选、反向对接和结构相似性评估已被用于预测小分子的新型生物靶标。此外,机器学习(包括有监督和无监督)的发展正不断赋能靶点识别流程。
AI驱动的靶点识别
近年来,业界见证了生物医学数据的爆炸式增长,覆盖从基础研究到临床试验的多个阶段。大量的数据为分析工作带来了挑战,也为人工智能搭建了舞台,让AI在生物标记物识别、适应症优先排序、类药分子设计、药代动力学性质预测、药物靶点相互作用、临床试验结果预测等方面做出显著贡献。
目前,多款人工智能赋能的药物已经进入临床阶段,如治疗非酒精性脂肪性肝炎的GS-0976、治疗实体瘤的EXS-21546,以及治疗特发性肺纤维化的 ISM001-055——这也是有史以来第一款进入临床验证阶段的AI赋能新药,靶向AI发现的创新靶点,拥有AI设计的新颖结构,现已在I期临床试验中取得积极初步结果并开启II期临床试验。
1、深度学习应用于靶点识别
深度学习又称深度神经网络,由多个隐藏节点层组成,通过这些节点层层递进,进行数据处理和特征提取。近年来,深度学习等基于机器学习的算法引起广泛关注。与传统的机器学习方法相比,基于深度学习的最新架构,如生成式对抗网络(GANs)、递归网络(recurrent network)等,已经在制药领域取得了卓越的成果。
举例而言,英矽智能于2022年7月宣布,公司与Answer ALS项目合作开展的肌萎缩侧索硬化症(ALS)靶点识别项目,成功发现28个经过验证的潜在靶点,其中18个(64%)在果蝇实验中被验证有效,涵盖8个未经报告过的基因。此次研究中,团队利用英矽智能自研人工智能平台PandaOmics分析了来自公共数据集的中枢神经系统(CNS)样本表达谱和由诱导性多功能干细胞分化成的运动神经元(diMN)表达谱,研究结果发表于同行评议期刊 Frontiers in Aging Neuroscience。
此外,大型语言模型还有助于通过快速生物医学文本挖掘发现治疗目标。基于大型语言模型的聊天功能,如微软 BioGPT和英矽智能ChatPandaGPT,可以在从数以百万计的出版物中提取的大量文本数据上进行预训练,进而将疾病、基因和生物过程联系起来,快速识别疾病发生发展的生物机制,和潜在药物靶点、生物标志物。然而,大型语言模型通常是在人类生成的文本上进行训练的,不一定具有判断数据准确性的能力,故存在无意中延续人类偏见的可能。
2、AI生成数据集辅助靶点识别
通过利用人工智能算法,研究人员模拟各种生物场景生成数据集,有望赋能罕见病研究等实验数据稀缺的治疗领域。然而,模型无法模拟其不理解的复杂数据,生成数据在不同种人群中的偏差,以及数据的质量控制和验证,是这一领域将面临的主要挑战。
3、靶点选择:新颖性和可信度的平衡
关于靶点选择标准,主要考虑的是与疾病的关联、成药性、毒性,以及新颖性。除实验方法外,研究人员常采用基于网络的分析法捕捉不同基因、蛋白质、药物和其他分子实体之间的关系,根据靶点在网络中的位置和连接状况判断靶点与疾病的关联。
成药性即候选分子调节特定靶点的能力,受到给药方式、蛋白质定位、类别、结构可用性等因素的影响。此外,研究人员还必须通过评估相关的细胞过程、基因本质和组织特异性来考虑靶点毒性。
Santos等人的研究(Santos, R. et al. (2017) A comprehensive map of molecular drug targets. Nat. Rev. Drug Discov. 16, 19–34)表明,获批药物中的大多数都靶向高度可信的靶点,新颖靶点占比很小。在人工智能辅助的靶点选择过程中,这一现状有望得到改变。
基于涉及科学出版物、基金和临床试验的海量数据,人工智能提取支持性和关联性证据,将潜在靶点与适应症联系起来,在促进新颖靶点发现的同时推动药物重定向(即“老药新用”),实现降本增效。
总结与展望
在广袤的化学空间和海量的“可成药靶点”中,人类已经完成探索的部分少之又少,产学研界迫切需要更高效的靶点识别策略。
版权声明 本网站所有注明“来源:生物谷”或“来源:bioon”的文字、图片和音视频资料,版权均属于生物谷网站所有。非经授权,任何媒体、网站或个人不得转载,否则将追究法律责任。取得书面授权转载时,须注明“来源:生物谷”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
