
中山大学最新论文登上Cell头条
来源:生物世界 2025-12-05 10:27
大语言模型能够帮助医生克服技术障碍,协助医生开展医疗人工智能研究,但也存在着幻觉和依赖性风险。
近日,来自中山大学中山眼科中心的一篇新论文登上了 Cell Press 官网头条。

该研究以:The effectiveness of large language models in medical AI research for physicians: A randomized controlled trial 为题,于 2025 年 11 月 26 日发表于 Cell 子刊 Cell Reports Medicine 上。中山大学中山眼科中心林浩添教授、陈文贲副研究员为论文共同通讯作者,尚元君博士、林远帆博士和李睿扬助理研究员为论文共同第一作者。
这项随机对照试验评估了大语言模型(LLM)在医学人工智能研究中对医生的有效性,结果显示,大语言模型能够帮助医生克服技术障碍,协助医生开展医疗人工智能研究,但也存在着幻觉和依赖性风险。

近年来,促进生物学、化学、物理学、材料科学、计算机科学和工程学等不同科学领域合作的跨学科研究,推动了众多科学领域的突破,并开辟了新的增长途径。例如,在数字医学领域,临床实践、计算机科学及其他学科的知识和技术的融合,极大地推动了医疗保健服务的提升、患者参与度的提高、临床结果的改善以及医疗保健系统的优化。
然而,尽管诸如人工智能(AI)之类的技术在生物医学领域展现出巨大的应用潜力,但其广泛应用却因技术障碍而受到极大限制。医生能够提供宝贵的临床见解和第一手经验,但由于缺乏必要的多学科专业知识或技能,以及难以获得工程技术人员的支持,他们在涉及 AI 技术的问题导向型研究中的参与可能会受到极大阻碍。对于那些身处偏远医院或大学的小型研究团队或临床团队,以及那些难以获取研究资源、跨学科合作和技术支持的年轻医生来说,这一挑战尤为明显。
在这项最新研究中,研究团队开展了一项优效性、开放标签的随机对照试验,招募了64名初级眼科医生,在最小化工程辅助的情况下进行为期两周的“自动化白内障识别”项目。其中干预组(32人)使用大语言模型(LLM)ChatGPT-3.5,对照组(32人)则不使用。
结果显示,干预组的项目总完成率高于对照组(87.5% vs. 25.0%),无辅助完成率同样更高(68.7% vs. 3.1%)。干预组展现出更优的项目规划能力和更短的完成时间。经过两周洗脱期后,41.2% 的成功干预组参与者在没有大语言模型(LLM)支持的情况下完成了新项目。
调查显示,42.6% 的参与者担心会不加理解地复述 AI 给出的信息,40.4% 的参与者担忧 AI 会助长惰性思维,这表明 AI 对于医生而言可能存在潜在依赖性风险。
因此,大语言模型虽能帮助医生克服技术障碍,但其长期风险仍需进一步研究。
该研究的核心发现:
大语言模型(LLM)协助医生开展医疗 AI 项目,完成率从 25% 提升至 87%;
在洗脱期后,41% 的成功干预医生能够独立完成新项目;
大语言模型使医疗 AI 研究民主化,但存在幻觉和依赖风险;
提出了与大语言模型有效互动的初步提示指南。
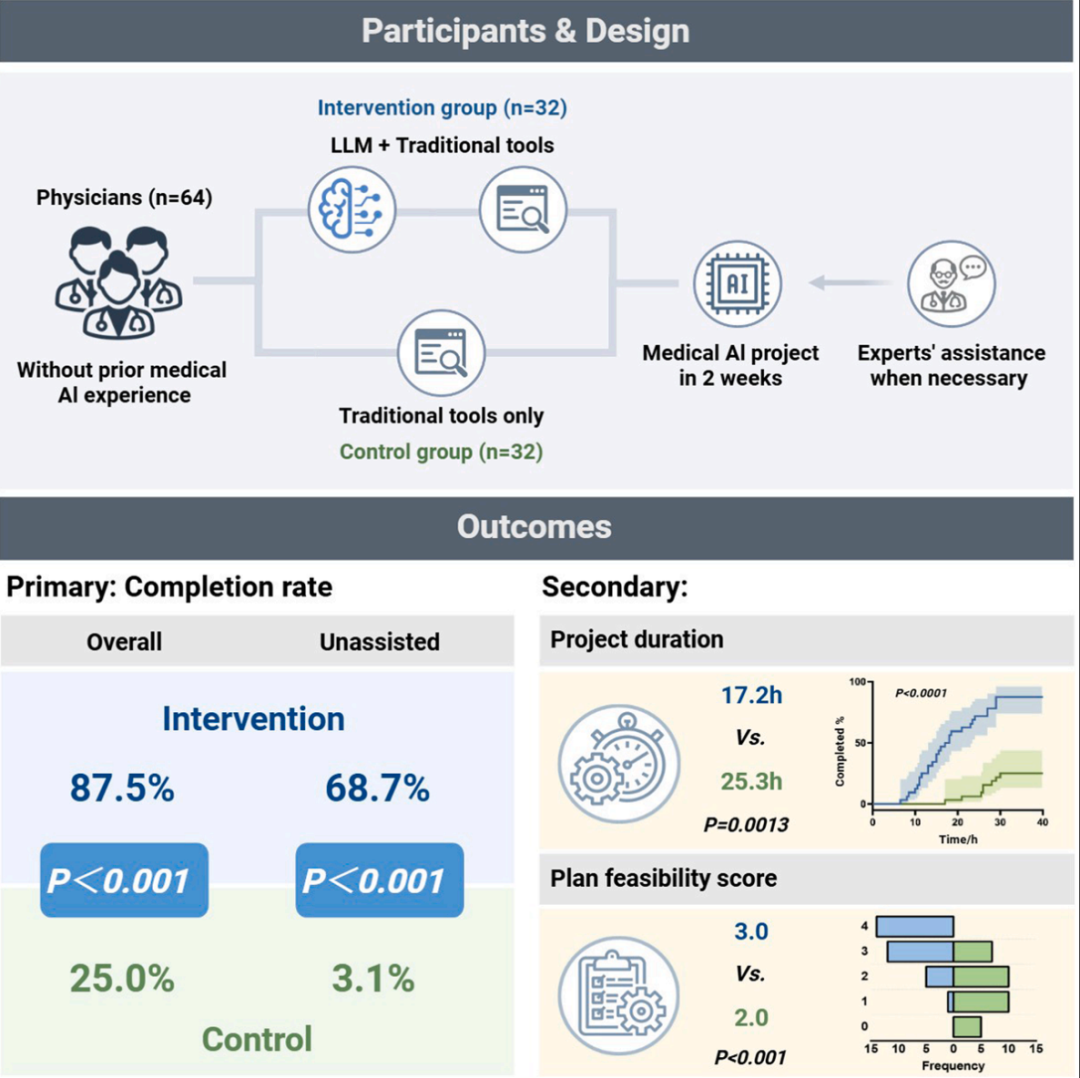
总的来说,这项研究证明,大语言模型(LLM)能够有效地帮助医生克服与医疗 AI 项目的设计、执行和报告相关的专业知识和技术障碍。然而,该研究也观察到使用大语言模型存在某些风险,例如 AI 的幻觉以及可能产生的依赖倾向。因此,还需要进一步的研究来评估长期使用大语言模型所形成的依赖风险。
论文链接:
https://www.cell.com/cell-reports-medicine/fulltext/S2666-3791(25)00542-7
版权声明 本网站所有注明“来源:生物谷”或“来源:bioon”的文字、图片和音视频资料,版权均属于生物谷网站所有。非经授权,任何媒体、网站或个人不得转载,否则将追究法律责任。取得书面授权转载时,须注明“来源:生物谷”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
