
微生物领域数据库及其分析系统建设研究取得进展
来源: 计算机网络信息中心 2022-04-11 08:09
微生物领域数据库及其分析系统建设方面取得新进展,提出了一种利用语义网技术构建知识图谱的方法,可将冠状病毒相关的毒株、基因组、蛋白序列、蛋白结构、抗体、文献和专利等多源异构数据映射至资源描述框架。
中国科学院计算机网络信息中心大数据技术与应用发展部与中科院微生物研究所等,在微生物领域数据库及其分析系统建设方面取得新进展,提出了一种利用语义网技术构建知识图谱的方法,可将冠状病毒相关的毒株、基因组、蛋白序列、蛋白结构、抗体、文献和专利等多源异构数据映射至资源描述框架(RDF),并构建了基于语义网框架的冠状病毒知识图谱数据库gcCov。gcCov包含六千多万条语义三元组,通过多源异构数据的语义整合,支持大规模数据驱动的知识发现,具备对基因、结构、抗体等数据进行相关性分析的能力,有助于推动未来对基本病毒机制以及药物和疫苗设计的研究。相关研究成果发表在mLife上。
近几十年来,冠状病毒持续威胁全球公共卫生安全。关于新型冠状病毒的研究十分广泛,相关出版物的数量也迅速增长。海量的科研数据促使将不同类型的研究整合到一个可搜索的语义互联的数据集,这颇具挑战性。目前,可用的冠状病毒数据库主要集中在基因组分析领域(如CovDB1和ViPR2)或出版物领域(如LitCovid3)。而这些数据库没有建立基因组数据和其他类型信息(如论文、专利和抗体)之间的相关性,阻碍了进一步的知识发现。
语义网能够将分布式网络资源集成到共享本体的知识库中,研究对象之间的潜在关系,是生物医学数据集成的有效解决方案。为了分析海量数据之间的相互关系,该研究设计了一套流水线方法,将不同来源的数据整合到语义网框架中。基于这一方法,该研究构建了gcCov数据库,使用关联开放数据(Link Open Data)提供有关冠状病毒的广泛信息和关联关系。gcCov是目前第一个也是唯一使用关联开放数据并基于语义网框架发布的冠状病毒数据库,有助于科学家检测链接数据之间的联系,从而发现隐藏在海量数据中的新知识。gcCov为当前的预防和治疗策略提供了线索,是满足冠状病毒研究日益增长的信息需求的重要工具。
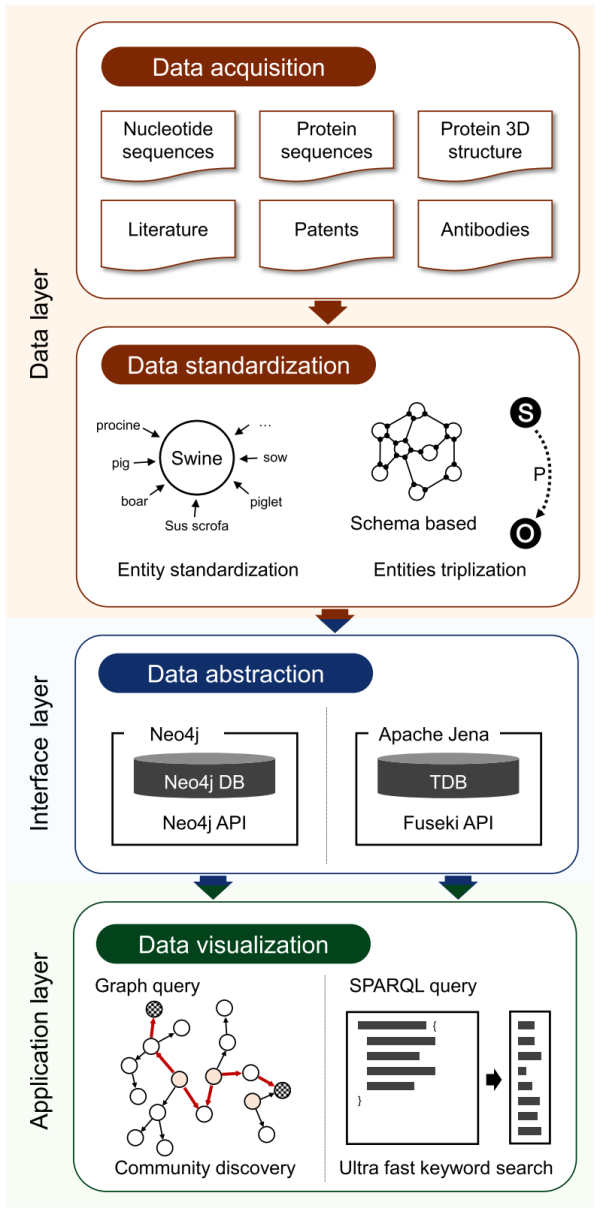
数据处理流水线示意图
版权声明 本网站所有注明“来源:生物谷”或“来源:bioon”的文字、图片和音视频资料,版权均属于生物谷网站所有。非经授权,任何媒体、网站或个人不得转载,否则将追究法律责任。取得书面授权转载时,须注明“来源:生物谷”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
