
科学家如何利用机器学习技术来改善人类健康研究?
来源:本站原创 2021-10-29 10:32
机器学习是一门多领域的交叉学科,主要包括概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科,近年来,科学家们不断将机器学习技术应用到改善人类健康和疾病等研究领域中,本文中,小编就整理了多篇研究报告,共同解读科学家如何利用机器学习技术来改善人类的健康。分享给大家!【1】Science:利用新型机器学习技术准确预测蛋白和RNA的三维结构doi:10.112
机器学习是一门多领域的交叉学科,主要包括概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科,近年来,科学家们不断将机器学习技术应用到改善人类健康和疾病等研究领域中,本文中,小编就整理了多篇研究报告,共同解读科学家如何利用机器学习技术来改善人类的健康。分享给大家!

一种新型的人工智能算法可以从错误的形状中识别出RNA分子的三维形状。对RNA折叠结构的计算预测尤其重要,也特别困难,因为已知的结构如此之少。
图片来源:Camille L.L. Townshend
【1】Science:利用新型机器学习技术准确预测蛋白和RNA的三维结构
doi:10.1126/science.abe5650
确定生物分子的三维形状是现代生物学和医学发现中最难的问题之一。公司和研究机构经常花费数百万美元来确定一个分子结构,即使采取这样大规模的努力也经常不成功。美国斯坦福大学博士生Stephan Eismann和Raphael Townshend在该大学计算机科学副教授Ron Dror的指导下,利用巧妙的新型机器学习技术,开发出一种通过计算预测准确结构来克服这一问题的人工智能算法。最值得注意的是,即使只从少数已知结构中学习,他们的方法仍然成功,这使得它适用于那些结构最难通过实验确定的分子类型。
他们的研究成果分别发表在2021年8月27日的Science期刊和2020年12月的Proteins期刊上,详细介绍了他们的方法在RNA分子和多蛋白复合物上的应用。发表在Science期刊上的这篇标题为“Geometric Deep Learning of RNA Structure”的论文是与斯坦福大学生物化学副教授Rhiju Das实验室合作完成的。这些作者设计的人工智能算法可以预测准确的分子结构,这样做可以让科学家们解释不同的分子是如何发挥作用的,其应用范围包括从基础生物研究到药物设计实践。
Eismann说,“蛋白质是执行各种功能的分子机器。为了执行它们的功能,蛋白质经常与其他蛋白质结合在一起。如果你知道一对蛋白质与某种疾病有关,并且你知道它们在三维中是如何相互作用的,你可以尝试用一种药物非常特异性地靶向这种相互作用。”
【2】Nature:基于机器学习的工具BoostDM可识别每种肿瘤类型的癌症驱动突变,有助开发个性化癌症治疗
doi:10.1038/s41586-021-03771-1
在一项新的研究中,来自西班牙巴塞罗那生物医学研究所的研究人员开发出一种计算工具,它可以识别每种肿瘤类型的癌症驱动突变。这一发现有助于加速癌症研究,并提供工具帮助肿瘤学家为每名患者选择最佳治疗方法。相关研究结果于2021年7月28日在线发表在Nature期刊上,论文标题为“In silico saturation mutagenesis of cancer genes”。
每种肿瘤---每名患者---都积累了许多突变,但并非所有的突变都与癌症的发展有关。在这项新的研究中,这些作者开发出一种基于机器学习方法的工具BoostDM,可以评估特定类型的肿瘤中所有可能的基因突变对癌症的发展和恶化的潜在贡献。
在之前提供给科学界和医学界的研究成果中,巴塞罗那生物医学研究所生物医学基因组学实验室已开发出一种方法来确定那些导致癌症发生、发展和扩散的基因。López-Bigas博士解释说,“BoostDM更进一步:它模拟了特定癌症类型的每个基因内可能发生的突变,并指出哪些基因是癌症过程中的关键。这些信息有助于我们了解肿瘤是如何在分子水平上引起的,它可以促进关于患者的最适合疗法的医疗决策。此外,该工具将有助于更好地了解不同组织中肿瘤发展的初始过程。”
这种新工具已经被整合到这些作者开发的IntOGen平台,旨在供科学界和医学界在研究项目中使用,并被整合到他们开发的癌症基因组解释器(Cancer Genome Interpreter)数据库中,该数据库更侧重于肿瘤医学家的临床决策。BoostDM目前正在研究从66种癌症中分析的28000个基因组的突变谱。BoostDM的应用范围将随着公众可获得的癌症基因组的增加而扩大。
【3】Nature子刊:通过机器学习模型识别复杂疾病的重要生物标记物
doi:10.1038/s41467-021-22756-2
随着高通量技术的发展,通过世界各地研究人员的共同努力,形成了大型公共数据库,如癌症基因组图谱(TCGA)。这对阐明疾病表型的分子机制具有重大意义。然而,由于癌症等复杂疾病的病理以及其在遗传、基因组和蛋白质组水平上复杂的分子机制,研究复杂的人类疾病仍具有挑战性。目前,已有很多基于机器学习的方法开发出来,包括非线性核支持向量机(SVMs)、随机森林(RFs)和人工智能领域的深度神经网络(DNNs),为药物反应和医学影像分类等临床相关的生物医学和生物组学数据建立了更强大的预测模型。然而这些模型算法较为复杂,存在信息不透明性,且难以解释每个单独特征的作用。然而,识别重要的生物标志物可以协助研究人员建立关于预防、诊断和治疗复杂人类疾病的新假设。
在本研究中,研究人员提出了一种基于排列的特征重要性测试(PermFIT),用于估计和测试特征的重要性。PermFIT(https://github.com/SkadiEye/deepTL)采用计算效率高的方式实现,无需模型改装。PermFIT可解释复杂框架中的单个特征,包括深度神经网络,随机森林和支持向量机。通过对TCGA肾癌数据和HITChip Atlas体重数据的应用展示, PermFIT程序进一步显示了其优越性能。通过PermFIT程序的特征选择显着提高了这些预测模型的性能。然而,值得指出的是,PermFIT的预测性能改善受限于每个机器学习模型框架的能力。例如,RF在建模交互项方面相对低效,因此PermFIT-RF的性能可能会受到具有基因-基因强交互作用的复杂性状的限制。总体上,PermFIT与DNN的结合始终显示了优越性能。
【4】Nat Med:开发出新型机器学习技术 或有望改善胎儿先天性心脏病等出生缺陷的筛查
doi:10.1038/s41591-021-01342-5
先天性心脏病(CHD,Congenital heart disease)是一种最常见的出生缺陷,胎儿超声筛查能提供5个心脏视图,而这些视图能帮助检测90%的复杂先天性心脏病,但在医学实践中,这种筛查的敏感性会低至30%。日前,一篇发表在国际杂志Nature Medicine上题为“An ensemble of neural networks provides expert-level prenatal detection of complex congenital heart disease”的研究报告中,来自加利福尼亚大学等机构的科学家们通过研究研究开发了一种新方法,其能将常规的超声成像与机器学习工具相结合,使得医生在检测孕妇子宫中绝大多数复杂的胎儿心脏缺陷上的准确率提高了一倍(当干预措施能够纠正或大大改善胎儿的生存机会)。
文章中,研究人员通过训练一组机器学习模型来模拟临床医生在诊断复杂先天性心脏病时缩遵循的任务;在世界范围内,人类在出生前能够发现的疾病仅有30%-50%的比例,然而,人类所执行超声检查和机器分析的结合就能帮助研究人员在检测数据集中发现95%的先天性心脏病。
美国和WHO推荐在孕妇中期妊娠时进行胎儿的超声检查,研究者表示,尤其是针对胎儿先天性心脏缺陷的诊断或能改善新生儿的预后并进一步开发子宫内疗法来改善胎儿的疾病进展。Arnaout教授说道,中期妊娠筛查是子宫内胎儿是男孩还是女孩的一种手段,但其也被用于筛查胎儿的出生缺陷。在该阶段的超声筛查通常会包括5个心脏视图,其能帮助研究人员诊断出高达90%的先天性心脏病,但在实际中,大约只有一半的病例是在非专家中心所检测到的。
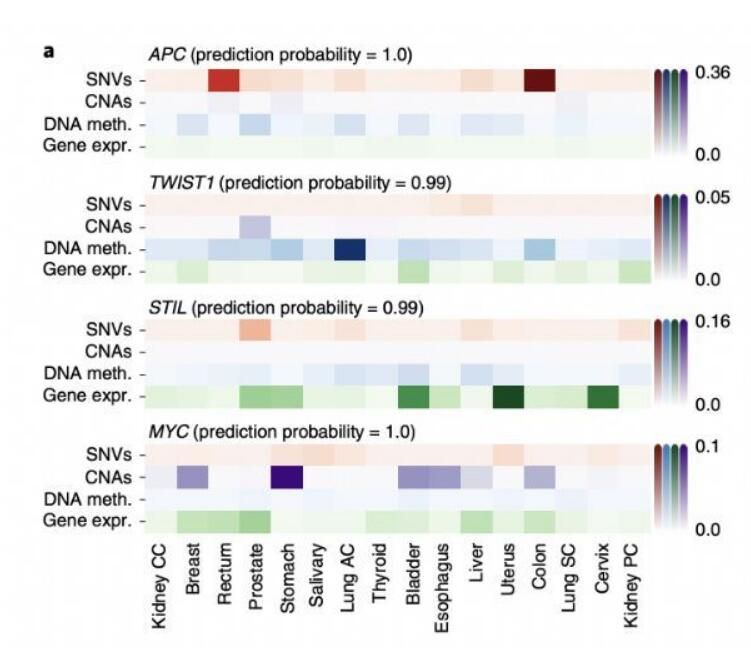
几种癌症基因模型的解释概括了其致癌分子机制。
【5】Nature 子刊:多组学数据与机器学习识别新的癌症基因
doi:10.1038/s42256-021-00325-y
2021年4月12日,德国慕尼黑环境卫生研究中心计算生物学研究所的研究团队在《Nature Machine Intelligence》期刊发表题为“Integration of multiomics data with graph convolutional networks to identify new cancer genes and their associated molecular mechanisms”的研究论文。该研究团队开发了一种基于图卷积网络的机器学习方法: EMOGI,通过将突变、拷贝数变化、DNA甲基化和基因表达等多组学泛癌数据与蛋白质-蛋白质相互作用(PPI)网络相结合来预测癌症基因。该研究团队预测了165个新的癌症基因,这些基因与PPI网络中已知的癌症驱动因素相互作用,而不是自身高度突变,新的预测还丰富了通过功能丧失筛查确定的必需基因。该方法能够找到由不同的分子改变而非高突变率定义的癌症基因类别,阐释了基因如何促进或阻碍肿瘤的发展和进展。
该研究团队开发的EMOGI以图卷积网络(GCNs)为基础,以半监督的方式进行训练,以区分假定的癌症和非癌症基因。通过EMOGI分析来自TCGA的16种癌症类型的基因组数据,输出了一个完全标记的图,其中每个基因都被分配了成为癌症基因的概率。接下来研究团队使用分层相关传播(LRP)进行特征重要性分析来解释由EMOGI鉴定的四个癌症基因(APC,TWIST1,STIL和MYC)的分子特征,还使用LRP规则提取了来自PPI网络的相互作用对单个基因分类的贡献,发现突变频率是癌症基因分类最重要的特征,尤其是对于最重要的预测。
【6】Blood Cancer Dis:基于机器学习的图像分析可可靠地识别血液恶性肿瘤
doi:10.1158/2643-3230.BCD-20-0162
骨髓增生异常综合症(MDS)是骨髓中干细胞的一种疾病,会干扰血细胞的成熟和分化。每年,大约有200名芬兰人被诊断患有MDS,可以发展为急性白血病。在全球范围内,MDS的发病率是每100,000人年4例。为了诊断MDS,还需要一个骨髓样本来研究骨髓细胞的遗传变化。
在赫尔辛基大学进行的研究中,使用基于机器学习的图像分析技术对MDS患者骨髓样本的显微图像进行了检查。样品用苏木精和曙红染色(H&E染色),数字化,并借助计算深度学习模型进行了分析;该研究发表在美国癌症研究协会期刊Blood Cancer Discovery杂志上。
通过使用机器学习,可以对数字图像数据集进行分析,以准确识别影响该综合征进展的最常见遗传突变,例如获得性突变和染色体畸变。样品中异常细胞的数量越多,预后模型生成的结果的可靠性就越高。
利用神经网络模型的最大挑战之一是了解标准,这些标准是它们根据数据得出结论的基础,例如图像中包含的信息。最近发布的研究成功地确定了在被教导寻找例如与MDS相关的基因突变时,在组织样本中会看到哪些深度学习模型。该技术提供了有关复杂疾病对骨髓细胞和周围组织影响的新信息。
【7】PNAS:科学家利用机器学习算法来识别人类基因组中的古老RNA病毒片段!
doi:10.1073/pnas.2010758118
近日,一篇发表在国际杂志Proceedings of the National Academy of Sciences上的研究报告中,来自日本多个研究机构的科学家们通过研究,成功利用机器学习算法来从人类基因组中识别古老的RNA病毒残留物,文章中,研究人员描述了他们如何教授AI系统来识别RNA病毒残留并利用其在人类基因组中搜索。此前研究结果表明,当个体被病毒感染后,病毒有时就会通过添加自身的RNA来改变宿主的DNA;而其它研究则表明,在很多年前能够感染群体的古老病毒有时会将其RNA残留物留在人类的基因组中,而寻找诸如此类残留物对于科学家们而言有着很大的挑战,因为每一种疑似病毒都需要进行大量的比较;而本文研究中,研究人员利用机器学习算法来帮助加速这一研究。
为了训练这种算法,研究人员利用来自已知非逆转录内源性RNA病毒元件的RNA,他们的想法就是通过利用现代病毒RNA来训练算法,这样这种系统就能了解病毒RNA的大体样子,研究者认为,这种共性可能存在于古代病毒的RNA中;当经过训练后,研究人员就能调整该系统来尽可能地预防多种假阳性结果的出现,随后他们就开始对人类基因组进行研究并识别出了将近100种可能性。对这些可能性分析后,研究者发现,许多的可能性都是已知的,许多可能性都低于他们所设定的门槛,最后就剩下了一种可能的未知病毒残留。
图片来源: Velazquez et al.(2020), Cell Systems。
【8】Cell Systems:科学家成功利用合成生物学和机器学习算法来加速人类肝脏类器官的开发
doi:10.1016/j.cels.2020.11.002
近日,一项刊登在国际杂志Cell Systems上的研究报告中,来自匹兹堡大学等机构的科学家们通过研究将合成生物学与机器学习算法相结合,利用血液和胆汁处理系统创建出了人体肝脏类器官,当植入到肝脏衰竭的小鼠体内后,实验室培养的替代肝脏就能有效延长小鼠的寿命。基于本文研究结果,未来研究人员或许有望在牺牲精度或控制的情况下诱发并加速实验室培养的器官的成熟。
医学博士Mo Ebrahimkhani指出,怀孕长达漫长的10个月,出生后机体的新生器官需要较长时间甚至数月才能够成熟,但如果一个人需要肝脏的话,或许等不了那么长时间;本文研究结果表明,我们能够在17天时间内得到具有四种主要细胞类型和血管的人类肝脏组织,同时只需要三个月时间就能让其发育成熟到妊娠晚期阶段的状态。
如今其他研究人员尝试使用生长因子在培养皿中诱导类器官的成熟,但这代价较高,而且会得到不一致的结果,且很容易发生人为错误;研究者表示,通常情况下会有不需要的组织或细胞类型出现,比如肠道细胞或脑细胞会生长在固体肝脏组织的中间。而遗传工程技术就比较干净,但其协调发挥作用起来较为复杂,于是研究人员就通过联合研究使用一种机器学习系统来逆向工程化人类肝脏成熟所必需的基因。
【9】Nat Commun:利用机器学习技术或能准确预测抗癌药物的作用效果
doi:10.1038/s41467-020-19313-8
近日,一项刊登在国际杂志Nature Communications上的研究报告中,来自韩国浦项科技大学等机构的科学家们通过研究表示,利用机器学习技术或能有效预测抗癌药物的治疗疗效。目前,随着药物基因组学的出现和发展,研究人员就能利用此前收集的患者对药物反应的数据所衍生的算法,进行机器学习研究来帮助预测不同患者对药物的反应,而输入尽可能多能反应个体药物反应的高质量学习数据或许也能作为一个研究起点来帮助改善机器学习预测的准确性。
相比人类临床研究数据而言,此前研究人员使用的动物模型临床前试验结果就能相对更加容易获得。这项研究中,研究人员使用与真人反应最接近的数据就能成功提高抗癌药物反应预测的准确性,研究人员开发的这种新型机器学习技术能利用算法从来自实际病人(而并非动物模型)的人工类器官中学习转录组学信息。研究者表示,即使相同类型癌症的患者也会对抗癌药物产生不同的反应,因此在癌症疗法的开发过程中,进行不同患者的定制治疗就显得尤为重要了;然而,目前研究人员的预测是基于癌细胞的遗传信息,这就限制了预测的准确性,由于不必要的生物标志物信息,因此机器学习也会出现基于错误信号的学习问题。
doi:10.1038/s41598-020-66907-9
最近,东欧芬兰大学和Kuopio大学医院最近发表的一篇文章报道了机器学习在帮助理解遗传和其他乳腺癌危险因素的相互作用中的应用。近年来的新发现已经确定了导致乳腺癌风险的几种风险因素。能够融合遗传(SNP)和非遗传风险因素的方法可以识别出罹患癌症的高风险人士,并能够制定适应风险的筛查计划,以更好地预防癌症。这可能会改善BC筛查的整体性能,并促进临床资源的有效分配。
在最近发表在Scientific Reports杂志上的研究中,作者利用机器学习分析了乳腺癌风险因素相互作用的新模型。该模型将所有已知和新发现的风险因素结合在一起,同时考虑它们之间的相互作用。东芬兰大学临床医学,病理学和法医学研究所开发的机器学习模型可以识别相互作用的遗传变异和乳腺癌的人口统计学危险因素的组合,从而可以有效地预测乳腺癌风险。(生物谷Bioon.com)
更多精彩盘点!敬请期待!

版权声明 本网站所有注明“来源:生物谷”或“来源:bioon”的文字、图片和音视频资料,版权均属于生物谷网站所有。非经授权,任何媒体、网站或个人不得转载,否则将追究法律责任。取得书面授权转载时,须注明“来源:生物谷”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
