
《自然·神经科学》:重大突破!科学家成功实现无创“读心术”,可根据fMRI监测的大脑活动重建连续语言序列
来源:垫高 2023-05-16 10:36
近日,美国德克萨斯大学奥汀分校的研究人员就研究出一种“读心”术。他们发现,
近日,美国德克萨斯大学奥汀分校的研究人员就研究出一种“读心”术。他们发现,大脑血氧水平依赖性(BOLD)信号包含丰富的语义信息,这些信息以单词或短语的形式被捕获。经过特异性训练的解码模型可以通过BOLD信号重建连续语言。
这种“读心”方式经由功能磁共振成像(fMRI),无需入侵大脑,并且具有个体特异性,由本人大脑活动训练得到的解码模型只适用于本人。
研究发表在《自然·神经科学》上[1]。

以往的脑机接口试验已经证实,通过将大脑和外部设备进行连接,我们可以获得一定的语言信息,实现交流的目的。但是,这种方法需要对受试者进行侵入性神经外科手术,并且使用范围有限。
相比之下,非侵入性的语言解码的适用范围可以更加广泛,有更广阔的应用前景。但是现有非侵入性大脑解码装置的识别范围还很小,也很难得到连贯的语言表达信息。
不得不说,想要解码大脑信息,fMRI是个很好的选择,最起码它不需要开颅,也有很好的空间特异性。但是,它所依赖的BOLD信号是个非常夸张的“慢性子”,神经活动反应到BOLD信号上,一次波动(上升和下降)大约需要10秒钟,对比英语的口语速度,一次信号波动差不多对应超过20个单词,解码难度实在是太大了!
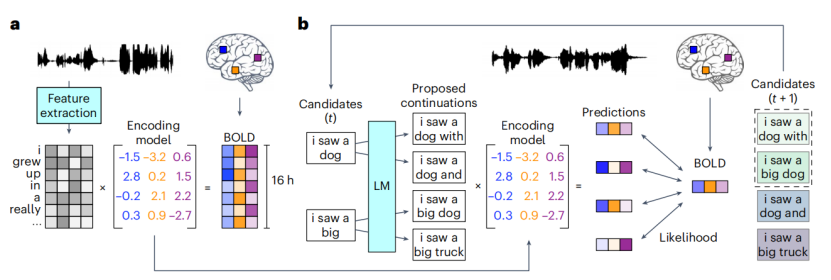
解码模型示意图
在此次研究中,研究人员设计了新的解码模型。首先,进行编码模型训练,通过记录受试者听到故事时的大脑活动,将单词和短语的语义特征与大脑活动对应。为了能够识别的语言符合语法规则并实现前后连贯,研究人员利用生成性神经网络语言模型和定向搜索算法,根据已知单词预测之后可能出现的语言序列,整个过程不断进行选择。
共有3名受试者参与了各自的解码模型训练,并用新故事对模型进行了测试。解码得到的语言序列不仅能够表达故事的大概含义,而且往往能够捕获精确的单词和短语,充分证明了我们完全有可能从BOLD信号中恢复细粒度语义信息。
为了测试解码模型的表达能力和准确程度,研究人员还做了一个小测试。他们将解码模型解码出的文本整理下来,拿给从未阅读过原文本的受试者阅读,还让受试者做阅读理解。结果显示,受试者16道题可以答出来9道。

解码模型输出文本比较
而且,这个解码模型并不是只能解码大脑的“视觉”,还可以解码大脑的“听觉”。研究人员让受试者在测试过程中看着空白屏幕,“听”一段新的故事,然后将模型解码结果和录音文本进行比较,平均识别准确率达到61%。
也就是说,语义表达在不同感官模态之间是共享的,非语言任务与语言任务的大脑响应相似,解码模型可以实现跨模态应用。
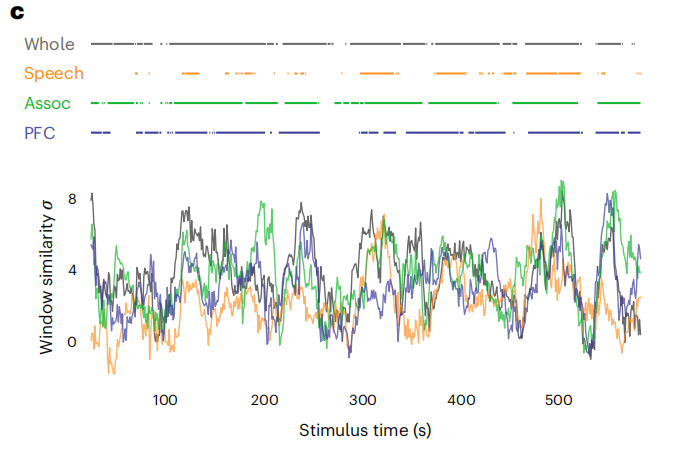
不同区域的解码时间点重合
研究人员将大脑皮层分为三个宏观区域,语音网络、顶叶-颞叶-枕叶结合区和前额叶区。为了确定哪些区域参与了语言处理,研究人员计算了每个区域被解码的时间点比例。结果显示,大部分解码的关键时间点都可以从顶叶-颞叶-枕叶结合区(80%-86%)和前额区(46%-77%)找到,语音网络只有28%-59%。
这也就意味着,大脑的语言表达是冗余编码的,我们既可以对整个大脑信号进行解码,也可以选择其中的特定区域进行记录和解码,提高实际应用的可行性和效率。
观看电影时大脑产生的语言序列
当然,不管是“读心术”还是“读脑术”,隐私性和伦理问题总是备受关注。研究人员尝试用其他受试者数据训练的解码模型来解码另一位受试者的大脑活动,但是解码模型的效果仅略高于随机猜测,远不能和相匹配的解码模型相媲美。并且,如果受试者有意识地进行抵抗,解码模型的准确率也会下降。
将大脑活动的BOLD信号解码为连续的语言,这无疑是非侵入性大脑-计算机接口的重要一步。在研究人员的设想中,之后的解码模型可能不再依赖个人的模型训练,而具有普适解码的能力。当然,由此带来的一系列问题,也必须在考虑之列。
参考资料:
[1] Tang J, LeBel A, Jain S, et al. Semantic reconstruction of continuous language from non-invasive brain recordings[J]. Nature Neuroscience, 2023: 1-9.
[2] https://www.nature.com/articles/d41586-023-01486-z
版权声明 本网站所有注明“来源:生物谷”或“来源:bioon”的文字、图片和音视频资料,版权均属于生物谷网站所有。非经授权,任何媒体、网站或个人不得转载,否则将追究法律责任。取得书面授权转载时,须注明“来源:生物谷”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
