
Cell Res:首个知识与数据联合驱动的多物种生命基础大模型GeneCompass,解析基因调控密码,打造干湿融合新范式
来源:生物探索 2024-10-12 10:56
研究人员开发的GeneCompass模型参数量超过1.3亿,是国际上首个融入先验知识的预训练基础大模型,探索了知识与数据联合驱动的新范式。
近年来,大语言模型(LLMs)已在自然语言、计算机视觉等通用领域引发了新一轮技术革命,通过大规模语料和模型参数进行预训练,LLMs能够掌握语言的共性规律,能够对多种下游任务产生质的提升,已经形成了新的人工智能范式。在生命科学领域,单细胞组学技术的突破产生了大量不同物种细胞的基因表达谱数据,形成了海量的生命“语料”。如果把基因表达值看作单词,组合在一起构成细胞“句子”,进而形成组织“段落”和器官“文章”,并将不同物种作为生命“语种”,利用LLMs相关技术有望构建系统精准破解基因密码的生命基础大模型,探索生命普遍存在的非线性基因调控机制,增进理解生命底层共性规律并创新各种重大疾病的诊疗手段。
2024年10月8日,中国科学院多个院所(包括中国科学院动物研究所、中国科学院计算技术研究所、中国科学院计算机网络信息中心、中国科学院自动化研究所、中国科学院数学与系统科学研究院等)组成多学科交叉研究团队“指南针联盟”(Xcompass Consortium),在Cell Research上发表了GeneCompass: Deciphering Universal Gene Regulatory Mechanisms with a Knowledge-Informed Cross-Species Foundation Model的研究论文。论文介绍了世界首个知识与数据联合驱动的多物种生命基础大模型GeneCompass,同时处理了人类和小鼠两个物种的转录组数据,包含了超过1.26亿个单细胞并覆盖3.6万个基因,融合了启动子序列、基因共表达关系、基因家族标注和基因调控关系等四种先验知识,基础大模型参数量达到1.3亿,实现了对基因表达调控规律的全景式学习理解,同时支持细胞状态变化预测及多种生命过程的精准分析,展示了人工智能赋能生命科学研究的巨大潜力。

数据集:多物种单细胞数据集
目前,全世界范围内在单一物种上已获得的单细胞转录组数据规模为千万级别,研究团队从美国(NCBI)、欧洲(EMBL-EBI)和中国(CNCB)等公开数据中收集了不同物种的单细胞转录组数据,人类和小鼠的同源基因采用相同的Ensembl ID表示,非同源基因则采用各自的Ensembl ID。经过筛选、清洗、均一化等预处理流程,建立了已知最大规模、包含人类和小鼠的超过1.26亿细胞、覆盖两个物种3.6万个基因、几乎全部已知细胞类型的高质量数据集scCompass-126M。
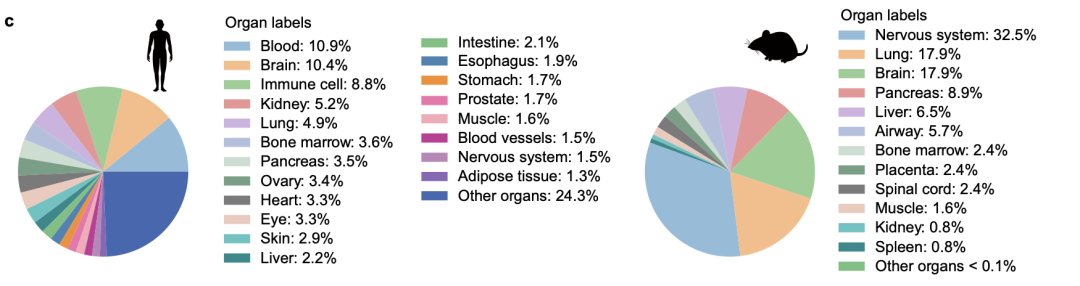
研究人员收集了1.26亿人类和小鼠的单细胞转录组数据(Credit: Cell Research)
模型架构:知识嵌入的生命基础大模型GeneCompass
研究人员开发的GeneCompass模型参数量超过1.3亿,是国际上首个融入先验知识的预训练基础大模型,探索了知识与数据联合驱动的新范式。GeneCompass采用gene2vec、DNABert等工具将启动子序列、已知基因调控网络、基因家族信息和基因共表达关系四种生物学先验知识进行编码,在单细胞转录组的基因ID和表达值基础上加入人类注释信息编码,提高了对生物数据间复杂特征关联关系的理解。通过训练整合不同物种的数据信息及先验知识,GeneCompass显著提升了多种下游任务的性能,有望进一步提高传统生物学研究的效率和精准性,为尚无法突破的复杂生命科学难题带来新的切入点。

GeneCompass融入四种生物学先验知识(Credit: Cell Research)
GeneCompass采用基于Transformer的深度学习架构,扩展传统的掩码语言模型Masked Auto Encoder(MAE)方式进行预训练,根据单细胞转录组的上下文同时预测掩码的基因及其基因表达,捕获不同基因之间在不同细胞背景下的长程动态关联,通过多任务联合预训练形成更加细粒度的生命基础大模型。预训练完成后,GeneCompass进一步应用于多种下游任务,用于对单细胞转录组数据进行编码,支撑细胞类型标注、基因扰动预测、药物反应预测和基因调控关系预测等任务。
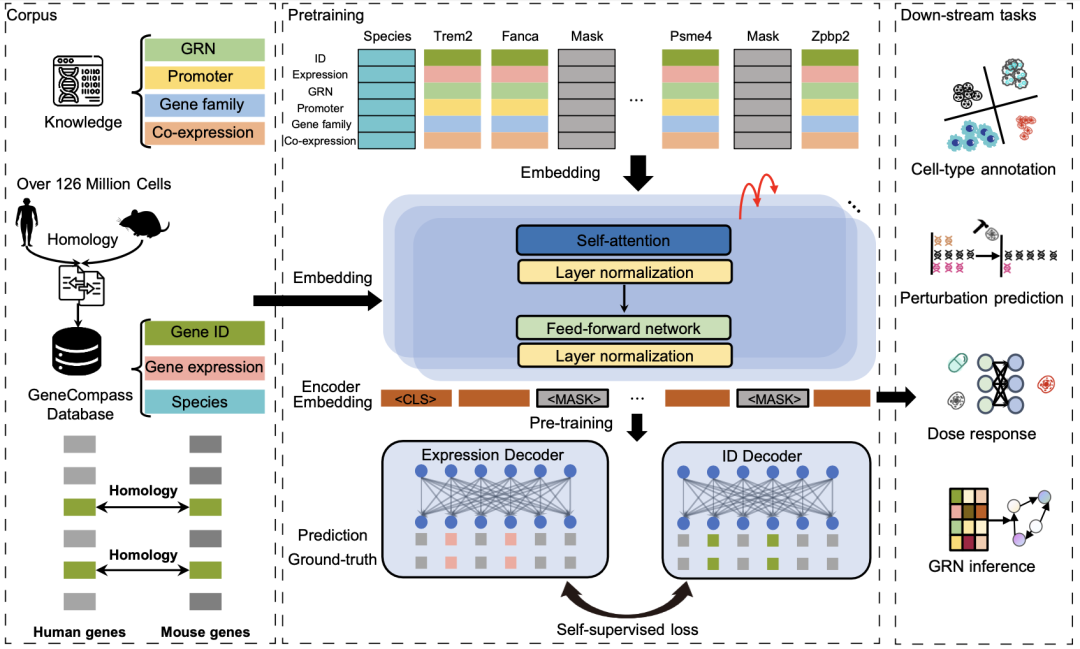
GeneCompass模型架构(Credit: Cell Research)
规模效应:多物种联合训练捕获生物进化保守规律
研究人员发现对大规模跨物种数据所获得的预训练模型对于单物种的子任务符合尺度定律(scaling law):即较大规模的多物种预训练数据量较单一物种数据量产生更优异的预训练表征,并进一步提高下游任务的性能。这一发现显示了物种间存在保守的基因调控规律,并且这些规律能够被预训练模型学习理解。这同时预示着随物种和数据的扩展,模型性能有望不断提升。
研究结果:GeneCompass具有跨物种表征能力
研究人员对人类和小鼠同一细胞类型(心肌细胞)中同源基因和非同源基因的GeneCompass编码进行了相似性分析,可以看出相较于非同源基因,不同物种的同源基因具有更相似的编码,同源基因在人类和小鼠之间也具有相似的基因调控关系。
研究人员将GeneCompass编码后的基因嵌入与跨物种细胞类型标注的SOTA方法CAME进行结合,发现在多种细胞尤其是视网膜细胞中,GeneCompass能够显著提升跨物种细胞类型标注的精度。这些结果都展示了GeneCompass通过多物种联合预训练获得了生命底层的共性规律,增强了基因表征的能力。
下游任务:基因扰动预测任务
研究人员利用GeneCompass编码的基因嵌入来预测由基因扰动所导致的全局基因表达变化,将其与现有工作GEARS结合起来,替换了原始从共表达知识图谱中学习到的基因嵌入。在前20个差异表达基因 (DEG) 的均方误差 (MSE) 平均降低了15.4%,使单基因扰动的偏差减少了5.9%,双基因扰动的偏差减少了12.5%。下图展示了双基因扰动TGFBR2+PRTG前20个基因表达变化, GeneCompass 的17/20 DEG预测结果比GEARS 的预测结果更准确。
下游任务:药物反应预测、基因调控预测、药物剂量反应预测、基因表达谱预测
GeneCompass作为生命基础大模型,支持直接使用(zero-shot)和微调(fine-tune)两种模式。基于此,研究人员在药物反应预测、基因调控预测、药物剂量反应预测、基因表达谱预测等多种下游任务上进行了充分实验,验证了GeneCompass在不同任务中的适配性。实验结果表明,GeneCompass 在不同下游任务中均可达到SOTA水平,相比于传统生物学方法对生命底层规律具有更深的理解。
下游任务:细胞命运预测和关键基因筛选
由于基因及其表达值在自监督预训练过程中同时被掩码和重建,GeneCompass能够捕捉复杂的调控机制,实现定量的模拟基因扰动。为了验证这种能力,研究人员构建iPSC模拟诱导实验,在人类成纤维细胞中模拟两个水平的OSKM 基因(Oct4、Sox2、Klf4 和 c-Myc)过表达。通过对比细胞状态嵌入的相似性可以看出,随着过表达水平的提高,成纤维细胞逐渐向iPSC细胞发育。这与现有结论是一致的,说明GeneCompass具有用于细胞命运预测的潜力。
此外,GeneCompass可通过模拟基因扰动分析预测细胞命运转变中的关键调控因子,有望提高湿实验的效率并揭示新机制。研究人员进行了人类ESC细胞向性腺细胞分化的实验,利用GeneCompass在ESC细胞上开展广泛的单基因模拟过表达。通过比较初始、模拟和目标细胞嵌入之间的余弦相似度,研究人员确定了五个潜在基因,即 NR2F1、NR5A1、WT1、TCF21 和 GATA4。其中三个( WT1、NR5A1 和 NR2F1)已有研究成果验证对小鼠体内性腺发育至关重要。进而,研究人员在 ESC 中分别过表达NR5A1和 GATA4,免疫荧光结果表明,在人类 ESC 中单独过表达任一基因均可诱导性腺基因。
综上所述,作为迄今为止最大规模的、具有知识嵌入的跨物种预训练生命基础大模型,GeneCompass可实现多个跨物种下游任务的迁移学习,并在细胞类型注释、定量基因扰动预测、药物敏感性分析等方面,相比已有方法取得更优性能。这充分展示了基于多物种无标注大数据预训练,再利用不同子任务数据进行模型微调的策略优势,有望成为实现基因-细胞特征相关联的各种生物问题分析预测的通用解决方案。
上述研究由“指南针联盟”团队完成,“指南针联盟”团队目前由北京干细胞与再生医学研究院/中国科学院动物研究所李鑫团队联合计算机网络信息中心,自动化研究所,计算技术研究所,数学与系统科学研究院等组成,联盟的目标是建立数智驱动的生命科学研究新范式,解析生命的本质规律。
版权声明 本网站所有注明“来源:生物谷”或“来源:bioon”的文字、图片和音视频资料,版权均属于生物谷网站所有。非经授权,任何媒体、网站或个人不得转载,否则将追究法律责任。取得书面授权转载时,须注明“来源:生物谷”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
